현대 서버 구조를 공부하다 보면 어느 순간부터는 “CPU 코어가 많다고 네트워크 처리도 자동으로 빨라지는 건 아니구나”라는 걸 느끼게 된다. 나도 예전에는 서버 CPU 코어 수만 많으면 네트워크 처리량도 그냥 비례해서 올라갈 줄 알았다. 실제로 멀티코어 CPU는 동시에 여러 작업을 처리할 수 있으니까 당연히 패킷 처리도 자연스럽게 분산될 것처럼 느껴졌기 때문이다. 그런데 NAPI, Interrupt Coalescing, DPDK 같은 구조들을 조금씩 이해하다 보니까 네트워크 패킷 처리에서는 “어떤 코어가 어떤 패킷을 처리하느냐” 자체가 굉장히 중요한 문제라는 걸 알게 됐다. 그리고 이런 흐름 속에서 등장한 핵심 기술 중 하나가 바로 RSS(Receive Side Scaling)다. 처음 이름만 들었을 때는 그냥 네트워크 속도 향상 기능 정도로 생각했는데, 구조를 이해하고 나니까 왜 최신 데이터센터와 Linux 서버에서 RSS를 굉장히 중요하게 보는지 조금 감이 오기 시작했다. 특히 인상 깊었던 건, 예전 네트워크 구조에서는 패킷 처리가 특정 CPU 코어 하나에 몰리는 경우가 많았다는 점이었다. 나도 처음에는 “멀티코어인데 왜 한 코어만 바쁘지?”라는 생각이 들었는데, 실제로 네트워크 처리 흐름은 CPU 계산과는 또 다른 병목 구조를 가지고 있었던 것이다.
예전 네트워크 구조에서는 특정 CPU 코어에 패킷 처리가 몰리기 쉬웠다
초기 네트워크 처리 구조에서는 네트워크 카드(NIC)가 들어오는 패킷을 하나의 수신 큐(Receive Queue)로 전달하고, CPU 특정 코어가 이를 처리하는 방식이 일반적이었다. 처음에는 나도 “패킷 처리 정도야 CPU가 알아서 분산하지 않을까?”라고 생각했는데, 실제로는 네트워크 인터럽트와 패킷 처리가 특정 코어에 집중되는 경우가 많았다고 한다. 특히 고속 네트워크 환경에서는 초당 엄청난 수의 패킷이 들어오기 때문에, 한 CPU 코어가 인터럽트 처리와 네트워크 스택 작업을 대부분 담당하게 되면 병목이 쉽게 발생할 수 있었다고 한다. 예를 들어 서버 CPU가 32코어여도 실제 네트워크 패킷 처리는 거의 Core 0 하나만 바쁘게 일하고 나머지 코어는 상대적으로 한가한 상황이 생길 수도 있었던 것이다. 나도 처음에는 멀티코어 CPU면 네트워크 패킷도 자연스럽게 병렬 처리되는 줄 알았는데, 실제로는 NIC 구조와 인터럽트 처리 방식 때문에 패킷 흐름 자체가 특정 코어로 쏠리는 경우가 많았다는 게 꽤 흥미로웠다. 특히 최신 데이터센터에서는 10Gbps, 100Gbps 같은 초고속 네트워크가 사용되기 때문에, 한 코어만 패킷을 처리하는 방식으로는 성능 한계가 빠르게 나타날 수 있다고 한다. 결국 현대 서버는 단순 CPU 코어 수 경쟁이 아니라, 네트워크 패킷을 여러 코어에 얼마나 효율적으로 분산시킬 수 있는가가 훨씬 중요한 시대가 되고 있었던 것이다.
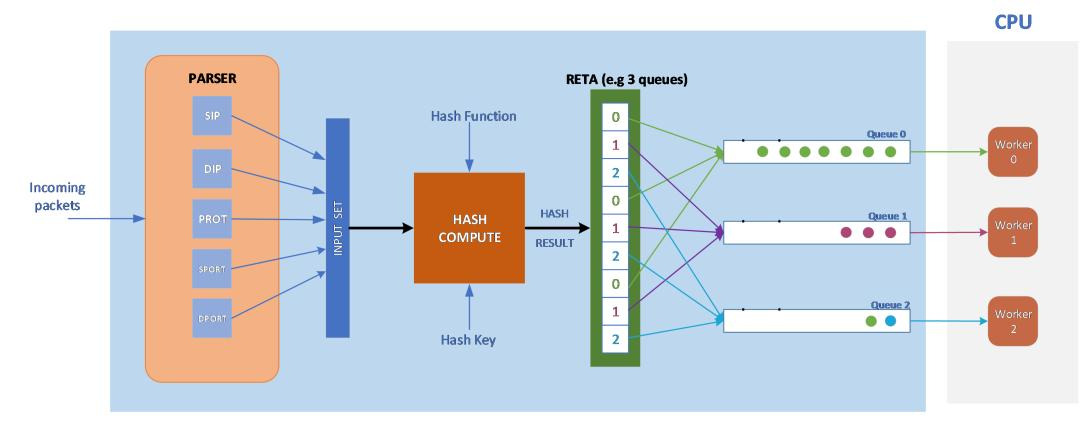
RSS는 패킷을 여러 CPU 코어로 나눠서 병렬 처리하게 만든다
RSS의 핵심은 굉장히 직관적이다. 바로 네트워크 패킷을 여러 CPU 코어에 분산해서 병렬 처리하게 만드는 것이다. 쉽게 말하면 NIC가 들어오는 패킷을 하나의 Receive Queue에 몰아넣는 대신, 여러 개 Queue로 나누고 CPU 코어별로 처리하게 만드는 구조에 가깝다. 특히 최신 NIC는 Multi-Queue 구조를 지원하는 경우가 많다고 한다. 즉 NIC 안에 여러 개 패킷 큐가 존재하고, RSS는 패킷 흐름(flow)을 해시(Hash) 기반으로 적절한 큐에 분산시킨다. 예를 들어 특정 TCP 연결 패킷들은 같은 코어로 유지하면서도, 전체 네트워크 트래픽은 여러 CPU 코어로 균형 있게 분산할 수 있는 것이다. 처음에는 나도 “그냥 랜덤으로 나누면 되는 거 아닌가?”라고 생각했는데, 실제로는 같은 연결(flow) 패킷이 서로 다른 코어로 분산되면 캐시 locality와 패킷 순서 문제가 생길 수 있기 때문에 Flow Hashing이 굉장히 중요하다고 한다. 결국 RSS는 단순 부하 분산이 아니라, 캐시 효율과 패킷 흐름 일관성까지 고려하는 구조였던 것이다. 나도 False Sharing과 Cache Coherency 문제를 공부하면서 “멀티코어 환경에서는 데이터를 어디서 처리하느냐 자체가 중요하다”는 걸 느끼게 됐는데, RSS 역시 완전히 같은 흐름 위에 있다는 게 꽤 인상 깊었다. 특히 RSS 덕분에 최신 서버는 여러 CPU 코어를 동시에 활용해 초고속 네트워크 패킷을 효율적으로 처리할 수 있게 되었고, 데이터센터 수준 트래픽도 훨씬 안정적으로 처리할 수 있게 되었다고 한다.
그래서 현대 데이터센터는 네트워크 패킷 locality까지 최적화하려고 한다
지금까지 공부했던 NUMA, Cache Coherency, DPDK, XDP 같은 기술들을 보면 공통된 방향이 있었다. 바로 CPU가 불필요하게 이동하거나 기다리지 않게 만들고, 데이터 흐름 자체를 최대한 locality 중심으로 최적화하는 것이다. RSS 역시 완전히 같은 흐름 위에 있다. 다만 이번에는 네트워크 패킷을 멀티코어 CPU에 어떻게 효율적으로 분산시킬 것인가가 핵심 문제인 것이다. 특히 최신 서버 CPU는 코어 수가 계속 증가하고 있고 네트워크 속도도 엄청 빨라지고 있기 때문에, 패킷 분산 구조 중요성도 훨씬 커지고 있다고 한다. 예를 들어 AI 데이터센터나 CDN 서버처럼 엄청난 네트워크 트래픽이 움직이는 환경에서는 특정 코어 하나가 병목이 되는 순간 전체 성능이 크게 떨어질 수 있다. 그래서 Linux 커널과 최신 NIC들은 RSS뿐만 아니라 RPS(Receive Packet Steering), RFS(Receive Flow Steering) 같은 추가적인 패킷 분산 최적화 구조까지 사용한다고 한다. 나도 처음에는 네트워크 성능이라는 게 단순 NIC 속도 경쟁인 줄 알았는데, 실제로는 패킷이 어느 CPU 코어에서 처리되고 캐시 locality가 어떻게 유지되는지까지 전부 성능에 영향을 준다는 게 꽤 흥미로웠다. 결국 현대 데이터센터는 단순히 “빠른 네트워크 카드”를 넘어서, 패킷과 CPU 코어 사이 흐름 자체를 얼마나 효율적으로 연결할 수 있는가를 경쟁하는 방향으로 계속 발전하고 있었던 것이다. 이걸 공부하면서 가장 인상 깊었던 건 현대 서버 성능은 단순 계산 속도 경쟁이 아니라, 데이터를 어떤 코어에서 얼마나 locality 좋게 처리할 수 있는가의 경쟁으로까지 진화하고 있다는 점이었다.
한 줄로 정리하면 RSS는 네트워크 카드가 패킷을 여러 Receive Queue와 CPU 코어에 분산하여 병렬 처리하도록 만드는 기술이며, 멀티코어 서버 환경에서 네트워크 병목을 줄이고 캐시 locality와 패킷 처리 성능을 높이는 중요한 최적화 구조다.